Trong bài viết này mình sẽ nói đến bài toán phân lớp và các phương pháp đánh giá 1 hệ thống phân lớp.
Mình sẽ sử dụng bộ dữ liệu MNIST, gồm 70.000 ảnh nhỏ của các số viết tay bởi người ở US. Mỗi ảnh được đánh nhãn với số tương ứng. Tập dữ liệu này được dùng cực kì phổ biến trong huấn luyện các thuật toán và thường được gọi là bộ dữ liệu “Hello World” trong Machine learning. Nói chung là ai học machine learning thì sớm hay muộn cũng phải sử dụng MNIST =))
Scikit-Learn cung cấp nhiều functions để tải về các bộ dữ liệu để huấn luyện. Trong đó có MNIST. Đoạn code sau đây để tải về dataset:
Sau đó xem kết quả
Có 70k ảnh và mỗi ảnh có 784 features. Bởi vì mỗi ảnh có 28×28 pixels và mỗi feature đơn giản được biểu diễn bởi 1 màu từ 0 (white) đến 255 (black).
Bây giờ ta thử xem 1 vài mẫu trong tập MNIST:
 Mẫu trong tập MNIST
Mẫu trong tập MNIST
Phân chia dữ liệu
Phân chia tập dữ liệu, chúng ta sẽ tiến hành chia bộ dữ liệu ra làm 2 phần: 1 phần để training (huấn luyện) gồm 60k ảnh đầu tiên và 1 phần để đánh giá (test) gồm 10k ảnh cuối của tập dữ liệu.
Để cho đơn giản, chúng ta sẽ tiến hành phân lớp với 1 số, trong ví dụ này là số 5. Bộ phát hiện số 5 được gọi là 1 bộ phân lớp nhị phân (đúng hoặc sai)
Chuẩn bị dữ liệu
Bây giờ chúng ta sẽ tạo tập dữ liệu để huấn luyện:
Xây dựng và huấn luyện mô hình
Sau khi đã có tập dữ liệu để huấn luyện, bây giờ chúng ta sẽ xác định bộ phân lớp phù hợp để thực hiện phân loại. Ở bài viết này mình sử dụng bộ phân lớp Stochastic Gradient Descent (SGD)
SGDClassifier dựa vào việc lấy ngẫu nhiên trong quá trình training (do đó được stochastic). Nếu bạn muốn kết quả không đổi sau mỗi lần chạy, bạn nên đặt thêm tham số random_state
Dự đoán kết quả sau khi huấn luyện
Sau khi huấn luyện xong chúng ta sẽ thực hiện chạy thử mô hình.
Sau khi đã chạy xong việc huấn luyện mô hình, chúng ta sẽ đi vào đánh giá độ chính xác mô hình trong việc dự đoán.
Cross-validation.
Phương pháp tốt nhất để đánh giá 1 mô hình học máy đó là cross-validation. Cross-validation là một phương pháp kiểm tra độ chính xác của 1 máy học dựa trên một tập dữ liệu học cho trước. Thay vì chỉ dùng một phần dữ liệu làm tập dữ liệu học thì cross-validation dùng toàn bộ dữ liệu để dạy cho máy. Ở bài này mình sẽ sử dụng K-fold, đây là phương pháp dùng toàn bộ dữ liệu và chia thành K tập con. Quá trình học của máy có K lần. Trong mỗi lần, một tập con được dùng để kiểm tra và K-1 tập còn lại dùng để dạy.
Để rút gọn thì thư viện sklearn đã cung cấp sẵn hàm để thực hiện:
Confusion Matrix
Một phương pháp tốt hơn để đánh giá performance của mô hình phân lớp đó là confusion matrix (ma trận nhầm lẫn). Ý tưởng chính là đếm số lần phần tử thuộc class A bị phân loại nhầm vào class B.
Để thực hiện tính toán ma trận nhầm lẫn, đầu tiên bạn phải có kết quả các dự đoán và so sánh với nhãn thật của nó. Nghĩa là chúng ta phải dự đoán trên tập test, sau đó dúng kết quả dự đoán này để so sánh với nhãn ban đầu.
Sau đó xác định ma trận nhầm lẫn:
Ma trận nhầm lẫn sẽ cho chúng ta nhiều thông tin về chất lượng của bộ phân lớp.
- TP (True Positive): Số lượng dự đoán chính xác. Là khi mô hình dự đoán đúng một số là số 5.
- TN (True Negative): Số lương dự đoán chính xác một cách gián tiếp. Là khi mô hình dự đoán đúng một số không phải số 5, tức là việc không chọn trường hợp số 5 là chính xác.
- FP (False Positive – Type 1 Error): Số lượng các dự đoán sai lệch. Là khi mô hình dự đoán một số là số 5 và số đó lại không phải là số 5
- FN (False Negative – Type 2 Error): Số lượng các dự đoán sai lệch một cách gián tiếp. Là khi mô hình dự đoán một số không phải số 5 nhưng số đó lại là số 5, tức là việc không chọn trường hợp số 5 là sai.
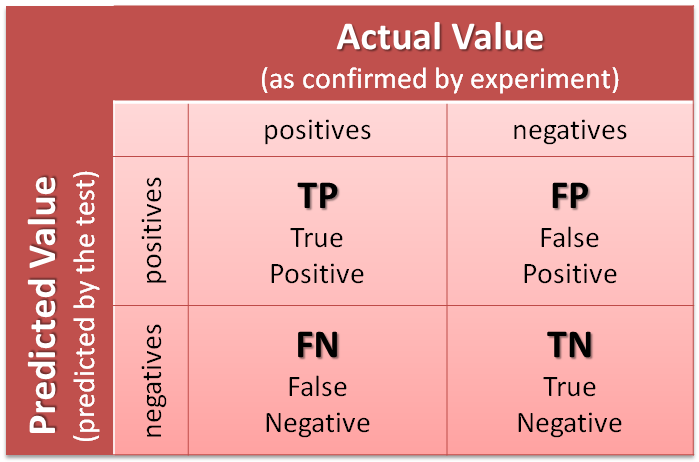 Giải thích về confusion matrix
Giải thích về confusion matrix
Từ 4 chỉ số này, ta có 2 con số để đánh giá mức độ tin cậy của một mô hình:
Precision and Recall
Precision: Trong tất cả các dự đoán Positive được đưa ra, bao nhiêu dự đoán là chính xác? Chỉ số này được tính theo công thức
precision = TP / (TP + FP)
Recall: Trong tất cả các trường hợp Positive, bao nhiêu trường hợp đã được dự đoán chính xác? Chỉ số này được tính theo công thức:
recall = TP / (TP + FN)
Để kết hợp 2 chỉ số này, người ta đưa ra chỉ số F1-score
F1-score
Một mô hình có chỉ số F-score cao chỉ khi cả 2 chỉ số Precision và Recall để cao. Một trong 2 chỉ số này thấp đều sẽ kéo điểm F-score xuống. Trường hợp xấu nhất khi 1 trong hai chỉ số Precison và Recall bằng 0 sẽ kéo điểm F-score về 0. Trường hợp tốt nhất khi cả điểm chỉ số đều đạt giá trị bằng 1, khi đó điểm F-score sẽ là 1.
Để tính F1-score, ta thực hiện như sau:
Tuy nhiên thì không phải lúc nào ta cũng cần đến F1, 1 vài trường hợp ta chỉ quan tâm đến precision, 1 vài trường hợp ta quan tâm đến recall. Ví dụ, nếu bạn huấn luyện 1 mô hình để phát hiện video an toàn cho trẻ em, bạn phải sử dụng bộ phân lớp mà có thể bỏ sót nhiều video an toàn (recall thấp) nhưng ít bỏ qua các video không an toàn (high precision). Hay còn gọi là giết nhầm còn hơn bỏ sót, thà không hiển thị video an toàn còn hơn là hiển thị video không an toàn.
Source Code: Các bạn có thể xem tại: https://github.com/dinhquy94/codecamp.vn/blob/master/bai3_4.ipynb
Trong bài này chúng ta sẽ tiếp tục với bài toán phân lớp cho nhiều lớp (multiclass classifiers), có thể phân biệt được nhiều hơn 2 lớp khác nhau.
Một vài các thuật toán (ví dụ như Random Forest hay naive Bayes) có khả năng xử lý bài toán đa lớp một cách trực tiếp. Các thuật toán khác (ví dụ như Support Vector Machine hay Linear classifiers) thì chỉ là các thuật toán phân lớp nhị phân nhưng vẫn có thể áp dụng cho bài toán phân đa lớp. Tùy vào bài toán mà chúng ta có chiến lược để sử dụng các thuật toán phân lớp khác nhau.
One-versus-all
Ví dụ để tạo ra một bộ phân lớp có thể phân loại được các ảnh của 10 chữ số (từ 0 đến 9), chúng ta sẽ phải huấn luyện 10 bộ phân lớp nhị để phát hiện ra lần lượt các chữ số (ví dụ bộ phát hiện chữ số 0, ví dụ bộ phát hiện chữ số 1, ví dụ bộ phát hiện chữ số 2…) Sau đó khi chúng ta muốn phân lớp 1 ảnh bất kì, ta sẽ đưa nó vào các bộ phát hiện này và mỗi lần thực hiện sẽ cho ra 1 decision score (khả năng xảy ra với mỗi bộ phân lớp). Sau đó kết quả sẽ là chữ số có bộ phân biệt cho kết quả decision score lớn nhất. Thuật toán này được gọi là one-versus-all (OvA – một với tất cả)
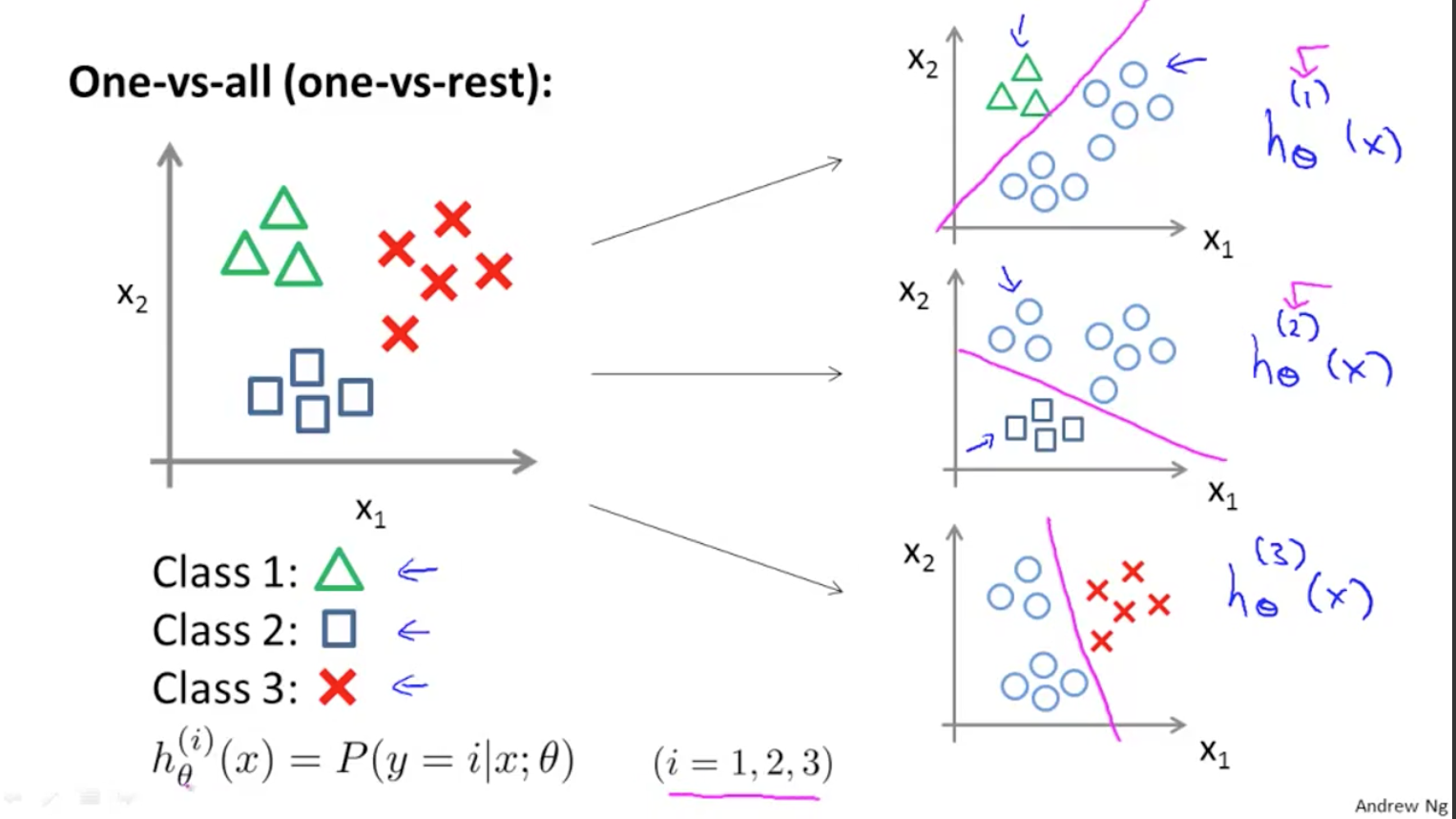 Giải thích về One-versus-all
Giải thích về One-versus-all
One-versus-one
Và 1 cách khác để tạo ra một bộ phân lớp có thể phân loại được các ảnh đó là chúng ta sẽ huấn luyện để cho mỗi số phân biệt với 10 chữ số còn lại bằng các bộ phân lớp nhị phân, như vậy mỗi số sẽ có 10 bộ phân lớp (bộ phân lớp số 1 với số 0, số 1 với số 2, số 1 với số 3…). Sau đó khi chúng ta muốn phân lớp 1 ảnh, chúng ta sẽ kết hợp kết quả của bộ dự đoán cho kết quả là True của mỗi bộ phân lớp. Đây được gọi là 1-vs-one (OvO). Nếu có N lớp thì số bộ phân lớp cần là: N × (N – 1) / 2
Trong hầu hết các thuật toán phân loại nhị phân thì OvA hay được sử dụng.
Trong thư viện Scikit-Learn, khi ta sử dụng thuật toán phân lớp nhị phân cho bài toán đa phân lớp nó sẽ tự động sử dụng thuật toán OVA để thực hiện đa phân lớp.
Đoạn code này huấn luyện mô hình phân lớp SGD trên tập huấn luyện gồm các lớp từ 0-9 (y_train) thay vì 5-vs-all (y_train_5) như ở bài trước. Về bản chất, Scikit-Learn sẽ tiến hành 10 bộ phân lớp nhị phân, sau đó lấy ra các decision score cho mỗi ảnh rồi chọn ra lớp có điểm cao nhất.
Để xem các decision scores, ta thực hiện như sau:
Điểm cao nhất sẽ thuộc về class 5
Nếu ta thực hiện phân loại với thuật toán cây ngẫu nhiên (Random Forest), thì chỉ cần thực hiện đơn giản như sau:
Lần này thì Random Forest sẽ không phải dùng đến 0-vs-all hoặc one-vs-one bởi vì Random Forest là thuật toán để phân lớp áp dụng cho bài toán đa phân lớp. Chúng ta có thể gọi hàm predict_proba() để lấy ra danh sách các xác suất mà mô hình phân lớp gán cho mỗi phần tử của lớp tương ứng.
Phân tích lỗi
Khi bạn thực hiện xong việc huấn luyện mô hình và cần phải cải thiện nó thì việc quan trọng là phải phân tích để giảm thiểu các lỗi mà nó gây ra.
Đầu tiên, bạn hãy nhìn vào ma trận nhầm lẫn. Chúng ta sẽ tiến hành dự đoán kết quả bằng hàm cross_val_predict(), sau đó gọi hàm confusion_matrix() như sau:
array([[5578, 0, 22, 7, 8, 45, 35, 5, 222, 1], [ 0, 6410, 35, 26, 4, 44, 4, 8, 198, 13], [ 28, 27, 5232, 100, 74, 27, 68, 37, 354, 11], [ 23, 18, 115, 5254, 2, 209, 26, 38, 373, 73], [ 11, 14, 45, 12, 5219, 11, 33, 26, 299, 172], [ 26, 16, 31, 173, 54, 4484, 76, 14, 482, 65], [ 31, 17, 45, 2, 42, 98, 5556, 3, 123, 1], [ 20, 10, 53, 27, 50, 13, 3, 5696, 173, 220], [ 17, 64, 47, 91, 3, 125, 24, 11, 5421, 48], [ 24, 18, 29, 67, 116, 39, 1, 174, 329, 5152]])
 confusion matrix
confusion matrix
Có nhiều số và thực sự là rất rối mắt để quan sát, vì vậy hãy biểu diễn nó sử dụng Matplotlib:
Hình này sẽ cho ta thấy các số phân loại vào đúng lớp của nó. Tuy nhiên nhìn kĩ thì có số 5 dường như có màu xám hơn so với các số còn lại. Điều này lý giải là có ít số 5 trong dataset được phân loại vào hoặc mô hình phân loại số 5 không tốt bằng các số khác. Trong trường hợp này là cả 2 khả năng đều có thể xảy ra.
Phân tích 1 cách kỹ hơn, chúng ta sẽ lấy lại công bằng cho trường hợp có ít hay nhiều số 5 hơn trong dataset, ta sẽ thực hiện chia các giá trị của confusion matrix cho tổng số các ảnh trong lớp đó, sau đó ta có thể so sánh các tỷ lệ lỗi giữa các lớp:
Tiếp theo chúng ta sẽ thay đường chéo bằng các số 0 để chỉ quan tâm đến tỷ lệ lỗi:
Quan sát kỹ hình ảnh này, phần tử cột thứ 8, hàng thứ 5 có màu sáng nhất so với các ô còn lại. Điều này cho ta thấy số 5 bị phân loại nhầm thành số 8 nhiều nhất (giá trị lỗi cao).
Qua bài này mình đã giới thiệu với mọi người 2 phương pháp để phân đa lớp trong machine learining và cách biểu diễn để phân tích lỗi cho các bài toán phân lớp. Bài sau mình sẽ giới thiệu các bạn bài toán gán nhiều nhãn cho 1 đối tượng.
Code của bài này các bạn có thể xem tại: https://github.com/dinhquy94/codecamp.vn/blob/master/bai3_4.ipynb
Top 20 confusion matrix là gì viết bởi Cosy
Bài 46 – Đánh giá mô hình phân loại trong ML – Khoa học dữ liệu
- Tác giả: phamdinhkhanh.github.io
- Ngày đăng: 02/24/2023
- Đánh giá: 4.59 (214 vote)
- Tóm tắt: Tại sao F1 score không là trung bình cộng precision và recall; 9. Accuracy và F1 score; 10. AUC; 11. Mối quan hệ giữa TPR và FPR …
- Nội Dung: Chính vì vậy bài viết này sẽ cung cấp cho các bạn kiến thức về các thước đo cơ bản nhất, thường được áp dụng trong các mô hình phân loại trong machine learning nhưng chúng ta đôi khi còn chưa nắm vững hoặc chưa biết cách áp dụng những thước đo này …
Các phương pháp đánh giá mô hình học máy, học sâu (Machine learning & Deep learning)
- Tác giả: rabiloo.com
- Ngày đăng: 10/26/2022
- Đánh giá: 4.43 (398 vote)
- Tóm tắt: Confusion matrix – ma trận hỗn loạn. Trong thực tế có ba độ đo chủ yếu để đánh giá một mô hình phân loại là Accuracy, Precision and Recall.
- Nội Dung: Một điều rất quan trọng là độ hỗn loạn của tập dữ liệu có thể được tăng lên đáng kể khi bạn xáo trộn dữ liệu trước khi chia tập dữ liệu ra thành nhiều phần nhỏ. Điều này giúp cho mỗi tập dữ liệu con có thể thể hiện rõ ràng hơn tính chất của tập dữ …
Bàn luận và đánh giá độ chính xác của thuật tốn
- Tác giả: 123docz.net
- Ngày đăng: 08/18/2022
- Đánh giá: 4.35 (586 vote)
- Tóm tắt: Để đánh giá độ chính xác của hàm mục tiêu người ta dung ma trận nhầm lẫn (Confusion Matrix). Ma trận là bảng (hai chiều). Cách thức tạo bảng (ma trận): …
- Nội Dung: Tỷ số độ lợi t ính đến số lượng và độ lớn của các nhánh khi chọn một thuộc tính để chia (phân hoạch), được tính bằng độ lợi thơng tin chia cho thơng tin của phân phối dữ liệu trên các nhánh. Đấy chính là tử tương cải biên của Thuật toán C4,5 được …
CONFUSION MATRIX LÀ GÌ
- Tác giả: benh.edu.vn
- Ngày đăng: 10/18/2022
- Đánh giá: 4.02 (327 vote)
- Tóm tắt: Confusion Matrix Là Gì. admin – 23/06/2021 337. Machine Learning merupakan salah satu cabang dari disiplin ilmu kecerdasan buatung (artificial intelligence) …
- Nội Dung: Machine Learning merupakan salah satu cabang dari disiplin ilmu kecerdasan buatan (artificial intelligence) yang membahas bagaimana sistem dibangun berdasarkan pada data. Jadi machine learning merupakan proses komputer untuk belajar dari data (learn …
Confusion Matrix và các công cụ đánh giá mô hình phân loại
- Tác giả: spiderum.com
- Ngày đăng: 11/30/2022
- Đánh giá: 3.94 (244 vote)
- Tóm tắt: Lại là câu chuyện về confusion matrix. … giải quyết mà cân nhắc tầm quan trọng của FN và FP, bạn cần ưu tiên cái gì hơn cho model của bạn.
- Nội Dung: Machine Learning merupakan salah satu cabang dari disiplin ilmu kecerdasan buatan (artificial intelligence) yang membahas bagaimana sistem dibangun berdasarkan pada data. Jadi machine learning merupakan proses komputer untuk belajar dari data (learn …
confusion matrix
- Tác giả: trituenhantao.io
- Ngày đăng: 10/13/2022
- Đánh giá: 3.73 (316 vote)
- Tóm tắt: Có thể dịch là (ma trận nhầm lẫn), là một bảng hiển thị trực quan hiệu quả của mô hình, đặc biệt là trên bài toán phân lớp nhiều nhãn. AI: Bạn muốn hỏi thêm gì …
- Nội Dung: Machine Learning merupakan salah satu cabang dari disiplin ilmu kecerdasan buatan (artificial intelligence) yang membahas bagaimana sistem dibangun berdasarkan pada data. Jadi machine learning merupakan proses komputer untuk belajar dari data (learn …
Mô hình machine learning là gì? Các bước xây dựng và phương pháp đánh giá mô hình học máy
- Tác giả: blog.cole.vn
- Ngày đăng: 07/24/2022
- Đánh giá: 3.54 (328 vote)
- Tóm tắt: Confusion Matrix (Đây không phải là 1 metric, nhưng rất quan trọng) · Classification Accuracy · Precision · Recall.
- Nội Dung: Ngoài ra còn có một metric khác dùng để đánh giá các mô hình hồi quy, được gọi là tỷ lệ Inlier. Metric này mình thấy cũng không có nhiều bài báo khoa học dùng, về cơ bản là tính tỷ lệ phần trăm các điểm dữ liệu được dự đoán có lỗi nhỏ hơn biên. Số …
Confusion Matrix
- Tác giả: filegi.com
- Ngày đăng: 09/26/2022
- Đánh giá: 3.25 (207 vote)
- Tóm tắt: A confusion matrix is a type of table construct that plays a specific role in machine learning and related engineering. It helps to show the prediction and …
- Nội Dung: Ngoài ra còn có một metric khác dùng để đánh giá các mô hình hồi quy, được gọi là tỷ lệ Inlier. Metric này mình thấy cũng không có nhiều bài báo khoa học dùng, về cơ bản là tính tỷ lệ phần trăm các điểm dữ liệu được dự đoán có lỗi nhỏ hơn biên. Số …
ĐÁNH GIÁ HIỆU NĂNG CỦA MÔ HÌNH PHÂN LỚP TRONG MACHINE LEARNING
- Tác giả: blog.unicloud.com.vn
- Ngày đăng: 02/28/2023
- Đánh giá: 3.09 (255 vote)
- Tóm tắt: Confusion matrix. Là một ma trận 2×2 đối với bài toán Phân lớp nhị phân (Binary classification) với nhãn thực tế ở một trục và trục còn lại …
- Nội Dung: Ngoài ra còn có một metric khác dùng để đánh giá các mô hình hồi quy, được gọi là tỷ lệ Inlier. Metric này mình thấy cũng không có nhiều bài báo khoa học dùng, về cơ bản là tính tỷ lệ phần trăm các điểm dữ liệu được dự đoán có lỗi nhỏ hơn biên. Số …
Understanding Confusion Matrix | by Sarang Narkhede
- Tác giả: towardsdatascience.com
- Ngày đăng: 05/27/2022
- Đánh giá: 2.91 (130 vote)
- Tóm tắt: When we get the data, after data cleaning, pre-processing, and wrangling, the first step we do is to feed it to an outstanding model and of course, …
- Nội Dung: Ngoài ra còn có một metric khác dùng để đánh giá các mô hình hồi quy, được gọi là tỷ lệ Inlier. Metric này mình thấy cũng không có nhiều bài báo khoa học dùng, về cơ bản là tính tỷ lệ phần trăm các điểm dữ liệu được dự đoán có lỗi nhỏ hơn biên. Số …
Confusion Matrix
- Tác giả: tek4.vn
- Ngày đăng: 12/24/2022
- Đánh giá: 2.88 (70 vote)
- Tóm tắt: Tất cả những gì hàm cần làm là lặp qua data loader chuyển các batch vào mô hình và nối kết quả của từng batch thành một tensor dự đoán trả về cho người gọi. @ …
- Nội Dung: Ngoài ra còn có một metric khác dùng để đánh giá các mô hình hồi quy, được gọi là tỷ lệ Inlier. Metric này mình thấy cũng không có nhiều bài báo khoa học dùng, về cơ bản là tính tỷ lệ phần trăm các điểm dữ liệu được dự đoán có lỗi nhỏ hơn biên. Số …
“Oánh giá” model AI theo cách Mì ăn liền – Chương 2. Precision, Recall và F Score
- Tác giả: miai.vn
- Ngày đăng: 11/09/2022
- Đánh giá: 2.64 (71 vote)
- Tóm tắt: Đấy, cái bảng Confusion Matrix nó chỉ có thế thôi. Bây giờ ta đi tìm hiểu các món bên dưới xem nó là cái gì nào. precision recall confusion …
- Nội Dung: Như vậy chúng ta đã có 2 khái niệm Precision và Recall và mong muốn 2 thằng này càng cao càng tốt. Tuy nhiên trong thực tế nếu ta điều chỉnh model để tăng Recall quá mức có thể dẫn đến Precision giảm và ngược lại, cố điều chỉnh model để tăng …
Phương pháp đánh giá mô hình phân loại (Classification)
- Tác giả: bigdatauni.com
- Ngày đăng: 11/25/2022
- Đánh giá: 2.62 (58 vote)
- Tóm tắt: Bảng dưới đây là Confusion Matrix tổng quát. · Precision (Positive PredictedValue) · Negative Predictive Value · Accuracy Rate · Error Rate · Sensitivity (Recall) …
- Nội Dung: Sensitivity (Recall) là tỷ lệ các trường hợp Positive thực sự (actual) đã được phân loại đúng. Lưu ý tránh nhầm lẫn với Precision. Sensitivity là tỷ lệ mà trong tất cả giá trị mà mô hình phân loại, có bao nhiêu giá trị (positive) thực sự đã được …
Quy trình hoàn chỉnh giúp phân loại dữ liệu hình ảnh
- Tác giả: vinbigdata.com
- Ngày đăng: 12/14/2022
- Đánh giá: 2.54 (174 vote)
- Tóm tắt: Diễn giải kết quả, ma trận lỗi (Confusion Matrix). Đây là một trong những bước quan trọng nhất mặc dù thường bị bỏ qua. Nguyên nhân là do dữ …
- Nội Dung: Ngoài một biến hiệu suất phụ thuộc để tối ưu hóa, bạn cũng có thể sử dụng trực quan hóa ma trận lỗi để có được thông tin chi tiết về dữ liệu của mình. Bằng cách hình dung các trường hợp được phân loại sai, bạn có thể hiểu rõ hơn về loại hình ảnh nào …
AI CLUB TUTORIALS
- Tác giả: tutorials.aiclub.cs.uit.edu.vn
- Ngày đăng: 03/19/2023
- Đánh giá: 2.37 (77 vote)
- Tóm tắt: Còn chần chờ gì nữa, hãy đến ngay với phần đầu tiên nhé! … Confusion matrix là một kỹ thuật đánh giá hiệu năng của mô hình cho các bài …
- Nội Dung: Các điểm màu cam đại diện cho mỗi threshold, ứng với trục tung là giá trị TPR và trục hoành là giá trị FPR. Nối các điểm màu cam lại với nhau ta được ROC curve. Đường đứt đoạn màu xanh đại diện cho kết quả của “no skill model” – mô hình dự đoán bằng …
Sign In
- Tác giả: rpubs.com
- Ngày đăng: 07/02/2022
- Đánh giá: 2.36 (178 vote)
- Tóm tắt: Confusion matrix là thuật ngữ của giới Machine learning, … MCC=0 cho thấy mô hình vô dụng (không hơn gì sự phán đoán ngẫu nhiên) còn …
- Nội Dung: Các điểm màu cam đại diện cho mỗi threshold, ứng với trục tung là giá trị TPR và trục hoành là giá trị FPR. Nối các điểm màu cam lại với nhau ta được ROC curve. Đường đứt đoạn màu xanh đại diện cho kết quả của “no skill model” – mô hình dự đoán bằng …
Trí tuệ nhân tạo: Các phương pháp đánh giá một mô hình phân loại
- Tác giả: tapit.vn
- Ngày đăng: 08/25/2022
- Đánh giá: 2.12 (132 vote)
- Tóm tắt: Tương tụ với predicted class cũng được coi là postive và negative. Sử dụng confusion matrix (ma trận nhầm lẫn) để có thể dễ dàng hình dung …
- Nội Dung: Đối với một sample nhất định, actual class có thể là postive và negative. Tương tụ với predicted class cũng được coi là postive và negative. Sử dụng confusion matrix (ma trận nhầm lẫn) để có thể dễ dàng hình dung kết quả của mô hình được trình bày ở …
Confusion matrix
- Tác giả: ongxuanhong.wordpress.com
- Ngày đăng: 03/17/2023
- Đánh giá: 2.02 (78 vote)
- Tóm tắt: trong XGBoost: thuật toán giành chiế… An trong Language Modeling là gì. Nam trong Lập trình Spark với Scala. iotsharing dotcom trong Góp nhặt …
- Nội Dung: Đối với một sample nhất định, actual class có thể là postive và negative. Tương tụ với predicted class cũng được coi là postive và negative. Sử dụng confusion matrix (ma trận nhầm lẫn) để có thể dễ dàng hình dung kết quả của mô hình được trình bày ở …
Khám phá f1 score là gì trong machine learning
- Tác giả: xaydungso.vn
- Ngày đăng: 11/03/2022
- Đánh giá: 2.09 (192 vote)
- Tóm tắt: Chủ đề: f1 score là gì F1 score là một số đo hiệu suất quan trọng trong bài … ta cần sử dụng nhiều phương pháp đánh giá khác nhau như Confusion Matrix, …
- Nội Dung: Đối với một sample nhất định, actual class có thể là postive và negative. Tương tụ với predicted class cũng được coi là postive và negative. Sử dụng confusion matrix (ma trận nhầm lẫn) để có thể dễ dàng hình dung kết quả của mô hình được trình bày ở …
CONFUSION MATRIX Tiếng việt là gì – trong Tiếng việt Dịch
- Tác giả: tr-ex.me
- Ngày đăng: 07/17/2022
- Đánh giá: 1.96 (103 vote)
- Tóm tắt: we often test accuracy using PCC(percent correct classification), along with a confusion matrix which breaks down the errors into false positives and false …
- Nội Dung: Đối với một sample nhất định, actual class có thể là postive và negative. Tương tụ với predicted class cũng được coi là postive và negative. Sử dụng confusion matrix (ma trận nhầm lẫn) để có thể dễ dàng hình dung kết quả của mô hình được trình bày ở …